并发模型
1.简介¶
数据库的Process Model指的是如何组织Worker并发地处理任务,其中单机意义下的Worker可以指进程或线程、分布式意义下的Worker可以指处理节点。
本节讨论数据库如何利用并发提高任务处理的效率、如何拆分任务、拆分数据以及I/O并发。
2.并发模型¶
数据库的单机Worker主要有两种,基于进程和基于线程。
在基于进程的Worker下,当数据库收到新的请求时,它可以利用fork或进程池对请求进行处理。
进程的任务分配依赖于操作系统,进程与进程之间利用共享内存等机制进行数据共享,且进程之间具有天然的隔离性。
进程的切换开销较大,且调度依赖于操作系统,因此更常见的方式是基于线程。
更轻量的上下文切换,系统可以自行掌控线程的任务分配方式,同时其天然地共享同一进程的空间,减少了系统调用的开销,都使得基于线程的Worker拥有更高的效率。
我们可以并发地处理多个任务,这称之为Inter-Query。而通过拆分任务然后并发地处理该任务的子任务,称之为Intra-Query。
3.Inter-Query¶
如果任务进行的操作都是只读的,那么任务之间不会相互影响,只需要顺序执行即可。
然而,一旦涉及写入的操作,那么任务和任务之间就需要进行协调。
这部分内容是事务与并发事务控制的讨论重点。
4.Intra-Query¶
主要思想是对任务进行拆分,最简单的方式为对任务的输入进行拆分,如利用两个线程同时构建Grace Hash Join的两个哈希表、在顺序扫描时不同的线程扫描其中一部分区域等。
有三种形式的拆分:
- 水平拆分:将同一操作下的任务拆分为互不相关的片段。
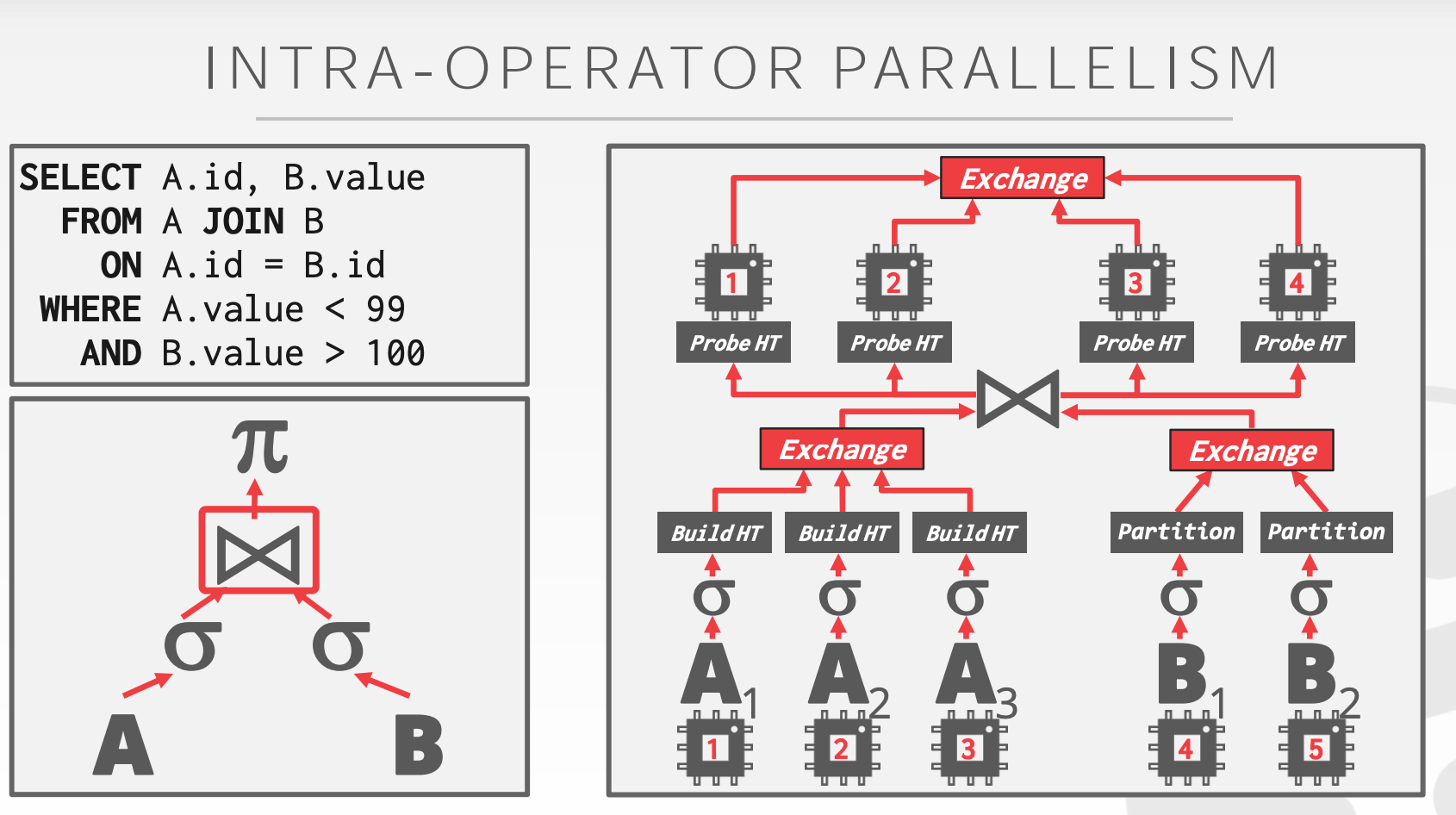
- 垂直拆分:指的Worker并发地处理不同的操作。类似生产者-消费者模型,父节点自旋等待来自子节点的数据,这就会造成一定程度的并发协调开销。
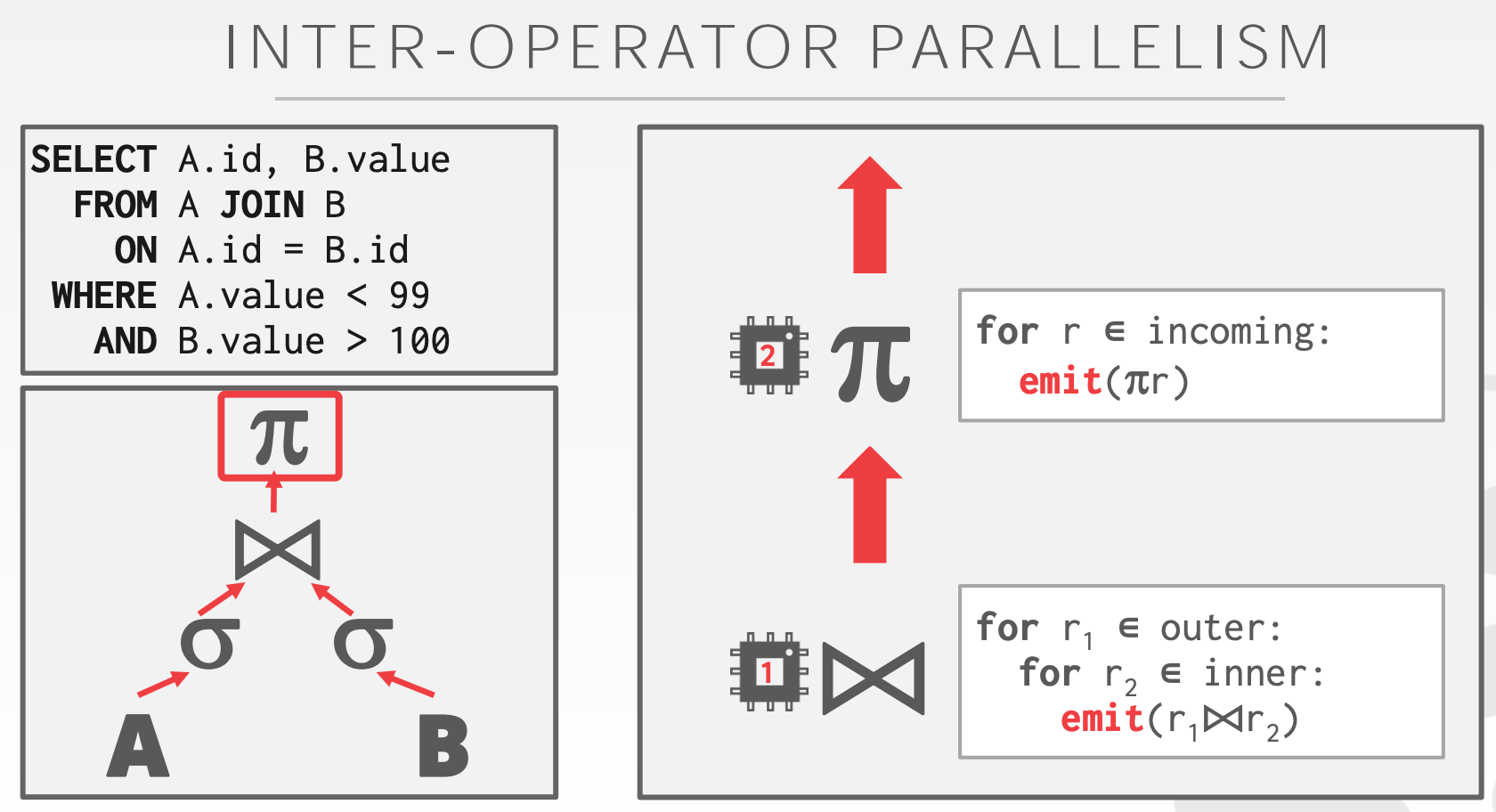
- Bushy Parallelism:垂直拆分的扩展,一个Worker可以同时处理多个不同的操作。
这些拆分并不是互斥的,实际上可对它们进行组合对任务进行处理。
5.并发磁盘I/O¶
由于木桶效应,磁盘数据库的速度主要取决于磁盘。常见的优化方式是采用多个磁盘,这样就可以从多个磁盘中并发读取数据,从而实现横向扩展。
然而,如果所需的数据都在同一磁盘上,读取速率仍然取决于单个磁盘。因此,需要对数据库进行拆分。
常见的分区方法有:
- 基于数据库的分区
- 基于表的分区
- 基于行的分区
- 基于列的分区:类似列式存储。
这里的分区讨论的是存储粒度,分配方法又可以利用Hash、Robin Round等算法进行分配。