处理模型
1.简介¶
数据库的处理模型指的是如何执行一个查询计划。
常见的模型有三种,对于不同的负载会采用不同的处理模型:
- Iterator Model
- Materialization Model
- Vectorized/Batch Model
2.Iterator Model¶
也称之为Pipeline Model。
在查询计划的逻辑树中,数据的传递是基于单个tuple,而不是传递的完整处理结果,就好像一个个tuple经过由处理节点组成的流水线(Pipeline)一样。
每一个逻辑树的节点会实现一个Next函数,其返回值是子节点的tuple处理结果。如果是叶子节点,它会直接从表中获取数据。
对于一个tuple来说,这种模型能够让我们在逻辑树中尽可能多的使用它,即尽可能的让多个逻辑节点去处理这个tuple。对基于磁盘的数据库来说,好处同样是明显的,因为它降低了与磁盘交互的可能性。
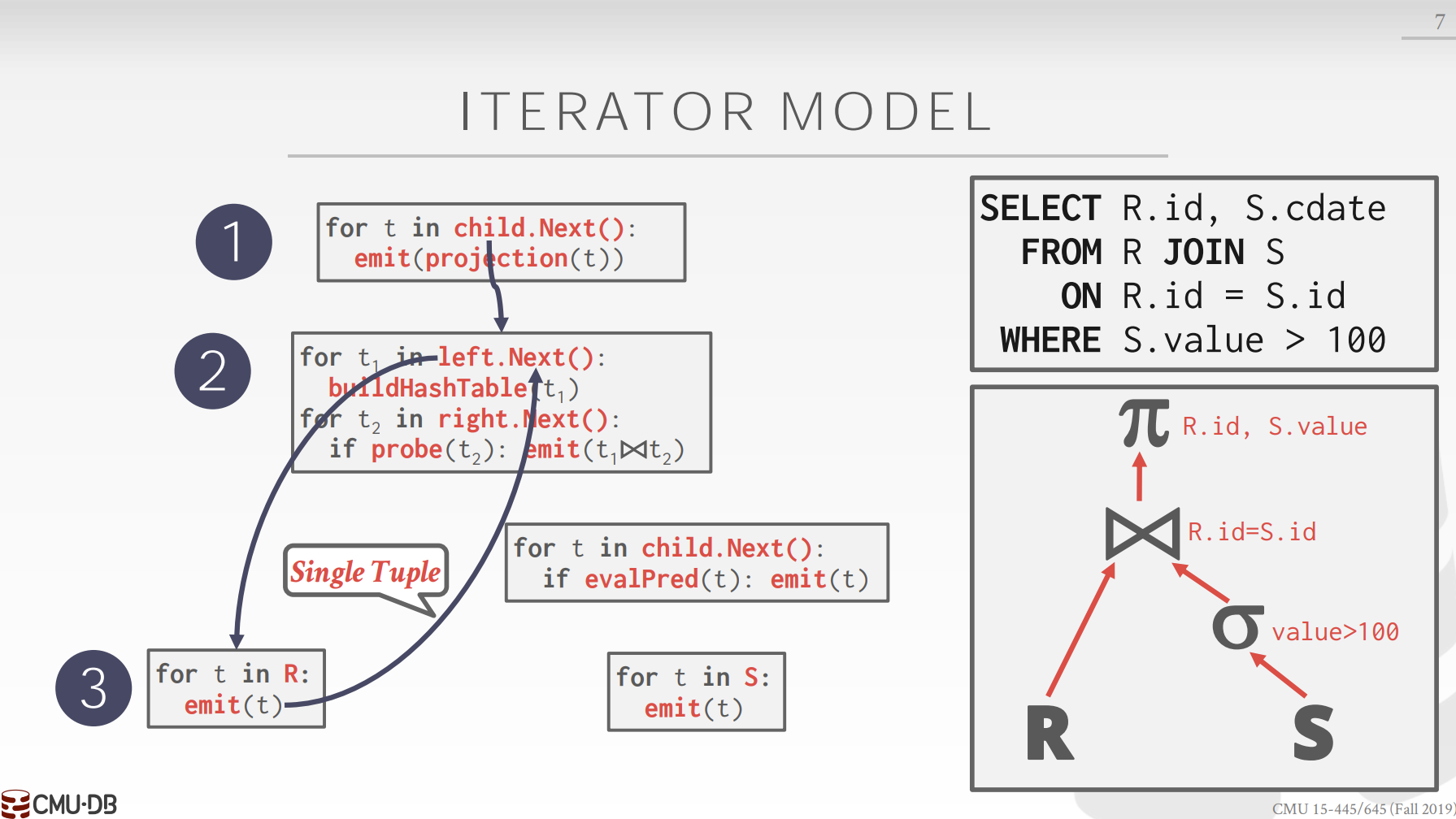
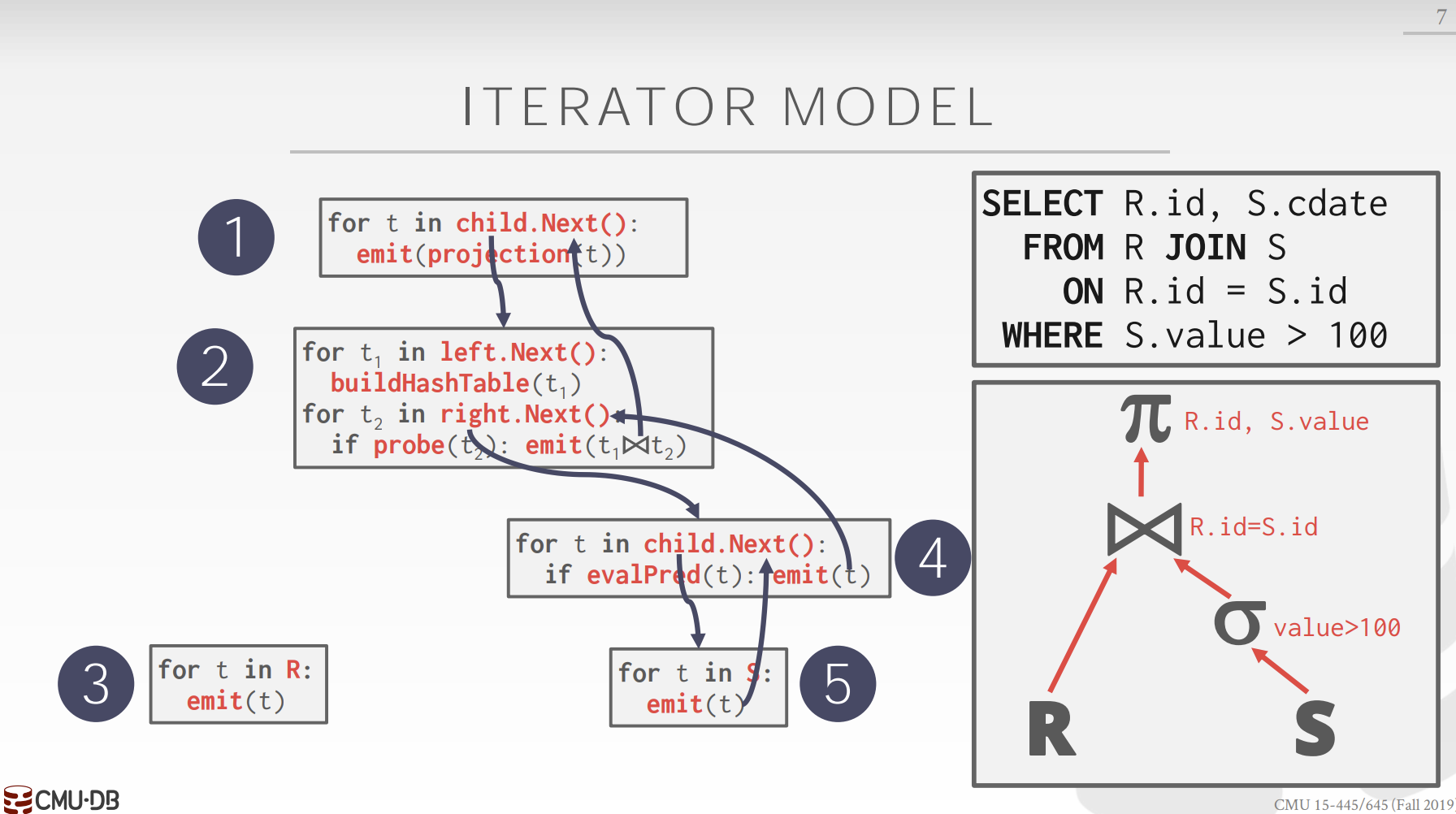
有一些操作必须要等待所有的Tuple才能执行,如Join、Subqueries、Order By,这些操作称之为Pipeline Breaker。
这种模型还可以很好的进行输出控制,如limit操作。若只需要得到十个输出,则在上层得到10个结果后不继续调用Next函数即可。
2.Materialization Model¶
该模型数据的传递是完整数据,而不是单个tuple。
该模型更适用于OLTP的负载,因为OLTP的涉及的规模较小,因此传递完整数据的开销较少。同理,对于OLAP的负载来说则不适用该模型。
3.Vectorization Model¶
基于Iterator Model的扩展,每次处理的是一组Tuple,一组Tuple的大小可以根据硬件做出优化调整。