成本估计
1.Relational Algebra Equivalences¶
对于可以生成同样的Tuple集合的关系代数表达式,我们称之为它们是逻辑等同的。
对于一个关系代数表达式,在不改变它的输出的前提下对其进行重写,从而获得更好的性能,称之为Query Rewriting。
对于Selection来说,常见的优化有:
- 尽早进行Filter
- 对条件进行重排序,将对数据更有选择性的条件提前执行。简单来说,就是尽快执行可以过滤掉更多数据的条件。
- 将复杂的条件进行拆分或简化。
对于Projection来说,常见的优化有:
- Projection Pushdown:尽早进行Projection,从而尽快获得更小的子集。
- 除了需要的数据(列)以外,尽可能的将不需要的数据(列)去除。
其他:
- 将不可能或不需要的条件去除,如WHERE 1 = 0。
- 尽可能将变量替换成常量,如X=Y AND Y=3可以替换为X=3 AND Y=3。
简单来说,优化的思想是尽可能快的获得更小的数据集,以及将不必要的条件去除。
2.成本预测¶
若想要知道每一个计划所需的成本,最简单的方法是每个计划都执行一遍,并返回最先得到结果的计划。但很显然这种做法开销过大了,目前只有MongoDB使用。
成本预测是一种估计方式,用于预测查询计划所需的成本,包括:
- 执行时间
- CPU使用率
- 磁盘I/O,是主要瓶颈
- 内存使用量
- 网络传输,常用于分布式系统
2.1.选择基数¶
为了进行成本预测,数据库内部会维护一个statistics catalog,用于跟踪表相关的信息。
该表并不是实事更新的,否则维护开销过大。一般数据库都会拥有相关的指令用于显式地更新该表,而如何隐式地维护该表取决于具体实现,可以以定时、执行事务时更新、表变化超过设定值时更新等。
对于每一张表,主要维护以下信息:
- N_R:Tuple数量。这是由于一张表中可能存在多版本的tuple,因此不能简单通过占用大小进行计算。
- V(A,R):对于属性A而言不同值的tuple数量。
通过这两个信息,可以计算出选择基数selection cardinalitySC(A,R),表示属性A的不同值平均出现的次数,由N_R/V(A,R)计算所得。
选择基数的假设是数据是均匀的。通过选择基数,我们可以估计在关系语法树上传递的数据量大小。
假设表中有10000个tuple,子节点对tuple的属性A进行条件判断,如WHERE A = 100。若有V(A,R)=1000,那么通过计算SC(A,R)=N_R/V(A,R) = 10,则可以估计出传递的数据规模为10个tuple。
选择率则是通过N_R/SC(A,R)计算得到,表示属性A满足条件的tuple期望数量。
期望预测作出的假设和问题主要为:
- 数据均匀分布:不一定。
- 条件相互独立:逻辑上没有关系的属性,在现实生活中可能有关联,从而导致数据倾斜。
- Join的两表之间,tuple存在对应关系:不一定。
2.2.直方图¶
数据库内部维护了直方图用于跟踪属性的值分布。
然而,为每个表的每个属性都维护一个确切的直方图,成本开销是巨大的。对于十亿个属性为32位的整数属性来说,就是4GB,且这只是其中的一个列。
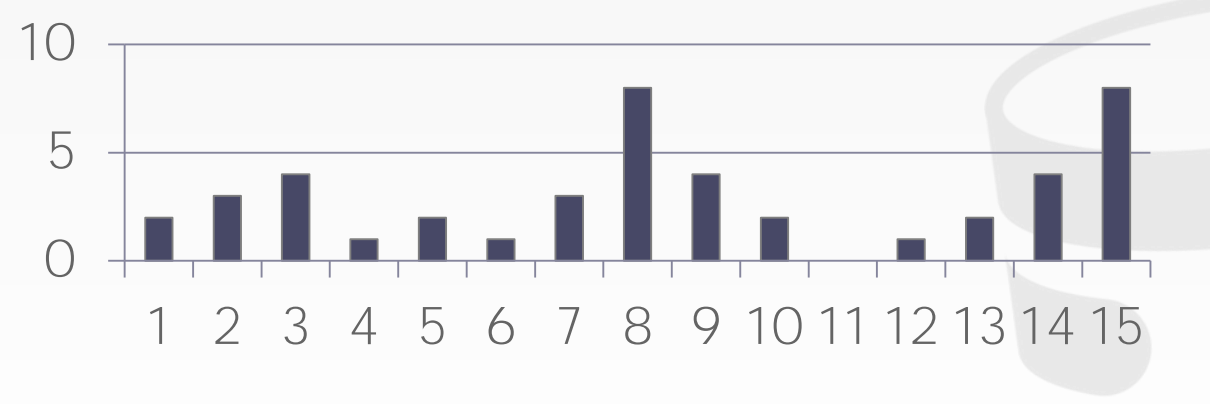
等宽直方图存储了一个范围内的值。如图所示,此时若需要估计属性为2的tuple数量,首先会从桶1中获得1-3的总数8,然后再用8除以桶所包含的数量3,从而得到2.6的估计值。
等宽直方图减少了一部分存储压力,相比选择基数的估算方式也减少了一部分倾斜误差,但无法得到桶内的精确值。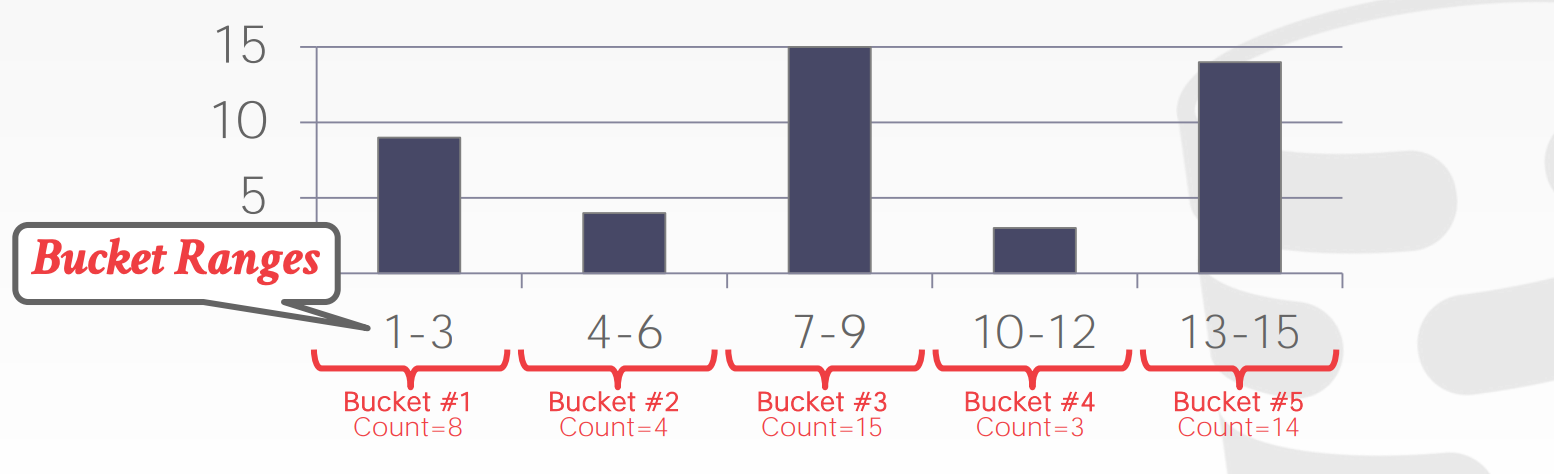
更好的方式是分位数桶,思想是使得每个桶的和都接近。
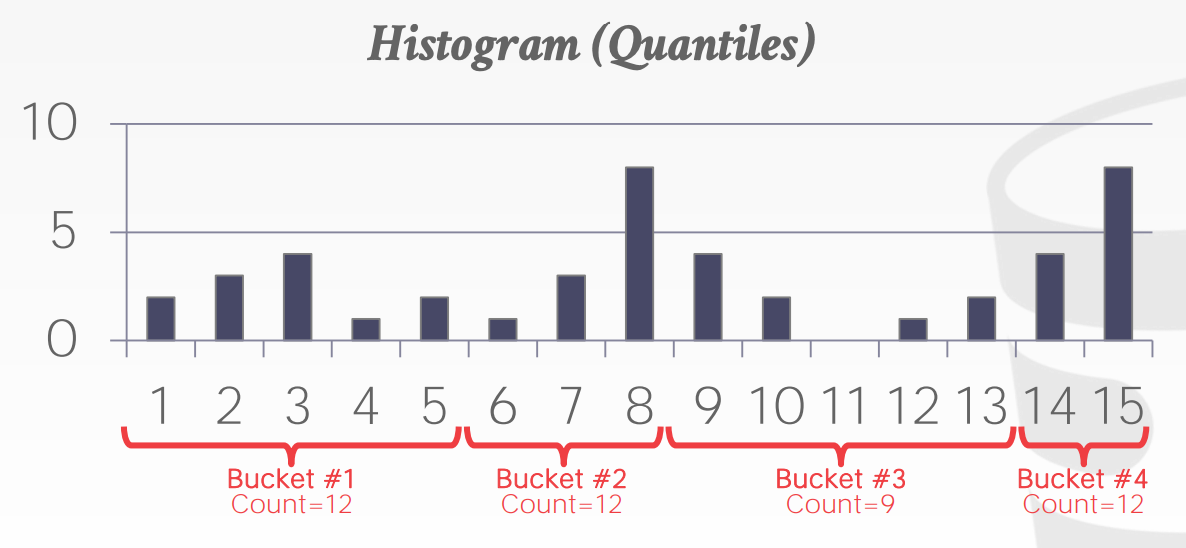
2.3.采样法¶
采样法通过随机对表中的tuple进行采样,从而得到一个表的子集,通过对采样表统计数据从而估计数据规模。